LSV-Loc: LiDAR to StreetView Image Cross-Modal Localization
Abstract
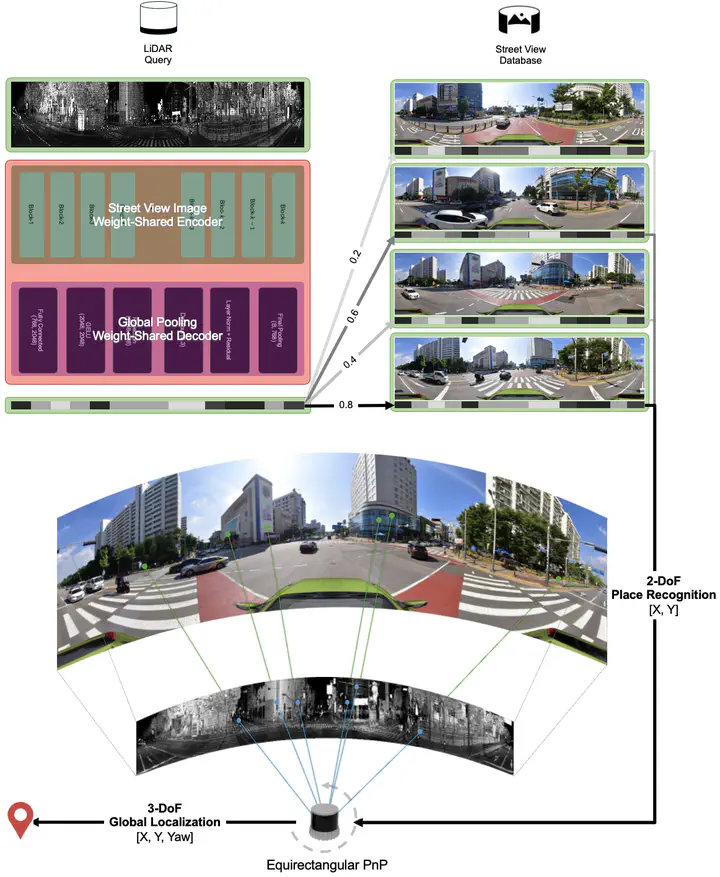
Accurate global localization remains a fundamental challenge in autonomous vehicle navigation. Traditional methods typically rely on high-definition (HD) maps generated through prior traverses or utilize auxiliary sensors, such as a global positioning system (GPS). However, the above approaches are often limited by high costs, scalability issues, and decreased reliability where GPS is unavailable. Moreover, prior methods require route-specific sensor calibration and impose modality-specific constraints, which restrict generalization across different sensor types. The proposed framework addresses this limitation by leveraging a shared embedding space, learned via a weight-sharing Vision Transformer (ViT) encoder, that aligns heterogeneous sensor modalities, Light Detection and Ranging (LiDAR) images, and geo-tagged StreetView panoramas. The proposed alignment enables reliable cross-modal retrieval and coarse-level localization without HD-map priors or route-specific calibration. Further, to address the heading inconsistency between query LiDAR and StreetView, an equirectangular perspective-n-point (PnP) solver is proposed to refine the relative pose through patch-level feature correspondences. As a result, the framework achieves coarse 3-degree-of-freedom (DoF) localization from a single LiDAR scan and publicly available StreetView imagery, bridging the gap between place recognition and metric localization. Experiments demonstrate that the proposed method achieves high recall and heading accuracy, offering scalability in urban settings covered by public Street View without reliance on HD maps.